 Home-theater-designers
Home-theater-designers
Kot analitik podatkov se boste pogosto soočili s potrebo po združevanju več naborov podatkov. To boste morali storiti, da dokončate svojo analizo in pridete do zaključka za svoje podjetje/deležnike.
Pogosto je težko predstaviti podatke, ko so shranjeni v različnih tabelah. V takšnih okoliščinah pridružitve izkažejo svojo vrednost, ne glede na programski jezik, na katerem delate.
MAKEUSEOF VIDEO DNEVA
Združevanja Python so kot združevanja SQL: združujejo nize podatkov tako, da se njihove vrstice ujemajo na skupnem indeksu.
Ustvarite dva podatkovna okvira za referenco
Če želite slediti zgledom v tem priročniku, lahko ustvarite dva vzorčna podatkovna okvira. Uporabite naslednjo kodo, da ustvarite prvi DataFrame, ki vsebuje ID, ime in priimek.
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)Za prvi korak uvozite pande knjižnica. Nato lahko uporabite spremenljivko, a , da shranite rezultat iz konstruktorja DataFrame. Konstruktorju posredujte slovar, ki vsebuje zahtevane vrednosti.
Na koncu prikažite vsebino vrednosti DataFrame s funkcijo tiskanja, da preverite, ali je vse videti tako, kot bi pričakovali.
Podobno lahko ustvarite drug DataFrame, b , ki vsebuje ID in vrednosti plače.
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)Izhod lahko preverite v konzoli ali IDE. Potrditi mora vsebino vaših DataFrames:
Kako se spoji razlikujejo od funkcije spajanja v Pythonu?
Knjižnica pandas je ena od glavnih knjižnic, ki jih lahko uporabite za manipulacijo DataFrames. Ker DataFrames vsebujejo več naborov podatkov, so v Pythonu na voljo različne funkcije za njihovo združevanje.
Python med mnogimi drugimi ponuja funkcije združevanja in združevanja, ki jih lahko uporabite za združevanje DataFrames. Med tema dvema funkcijama obstaja velika razlika, ki jo morate imeti v mislih, preden jo uporabite.
Funkcija združevanja združi dva podatkovna okvira na podlagi njunih vrednosti indeksa. The funkcija spajanja združuje DataFrames na podlagi vrednosti indeksa in stolpcev.
Kaj morate vedeti o pridružitvah v Pythonu?
Pred razpravo o vrstah združevanj, ki so na voljo, upoštevajte nekaj pomembnih stvari:
kako narediti sliko 1920x1080
- SQL spoji so ena najosnovnejših funkcij in so precej podobni Pythonovim spojem.
- Če se želite pridružiti DataFrames, lahko uporabite pandas.DataFrame.join() metoda.
- Privzeto združevanje izvede levo združevanje, medtem ko funkcija spajanja izvede notranje združevanje.
Privzeta sintaksa za pridružitev Python je naslednja:
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)Prikličite metodo pridružitve na prvem DataFrameu in posredujte drugi DataFrame kot njegov prvi parameter, drugo . Preostali argumenti so:
- na , ki poimenuje indeks, ki se mu pridruži, če jih je več.
- kako , ki definira vrsto spoja, vključno z notranjim, zunanjim, levim in desnim.
- pripona , ki definira levi priponski niz imena vašega stolpca.
- rsuffix , ki definira desni priponski niz imena vašega stolpca.
- vrsta , ki je logična vrednost, ki označuje, ali je treba razvrstiti nastali podatkovni okvir.
Naučite se uporabljati različne vrste združevanj v Pythonu
Python ima nekaj možnosti pridružitve, ki jih lahko uporabite, odvisno od trenutne potrebe. Tukaj so vrste pridružitev:
1. Leva pridružitev
Levo združevanje ohrani vrednosti prvega podatkovnega okvira nedotaknjene, medtem ko vnese ujemajoče se vrednosti iz drugega. Na primer, če želite vnesti ujemajoče se vrednosti iz b , ga lahko definirate na naslednji način:
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)Ko se poizvedba izvede, izhod vsebuje naslednje sklice na stolpce:
- ID_levo
- Fname
- Lname
- ID_desno
- Plača
To združevanje potegne prve tri stolpce iz prvega DataFramea in zadnja dva stolpca iz drugega DataFramea. Uporabilo je pripona in rsuffix vrednosti za preimenovanje stolpcev ID-jev iz obeh naborov podatkov, s čimer zagotovite, da so nastala imena polj unikatna.
Rezultat je naslednji:

2. Desna pridružitev
Desno združevanje ohrani vrednosti drugega DataFrame nedotaknjene, hkrati pa vnese ujemajoče se vrednosti iz prve tabele. Na primer, če želite vnesti ujemajoče se vrednosti iz a , ga lahko definirate na naslednji način:
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)Rezultat je naslednji:
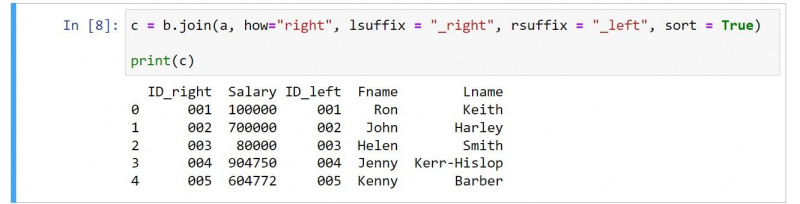
Če pregledate kodo, je nekaj očitnih sprememb. Na primer, rezultat vključuje stolpce drugega okvira DataFrame pred tistimi iz prvega okvira podatkov.
Uporabiti morate vrednost prav za kako argument za podajanje desnega združevanja. Upoštevajte tudi, kako lahko preklopite pripona in rsuffix vrednosti, ki odražajo naravo pravega pridružitve.
V običajnih združevanjih boste morda pogosteje uporabljali leva, notranja in zunanja združevanja v primerjavi z desnim združevanjem. Vendar pa je uporaba v celoti odvisna od vaših podatkovnih potreb.
3. Notranji spoj
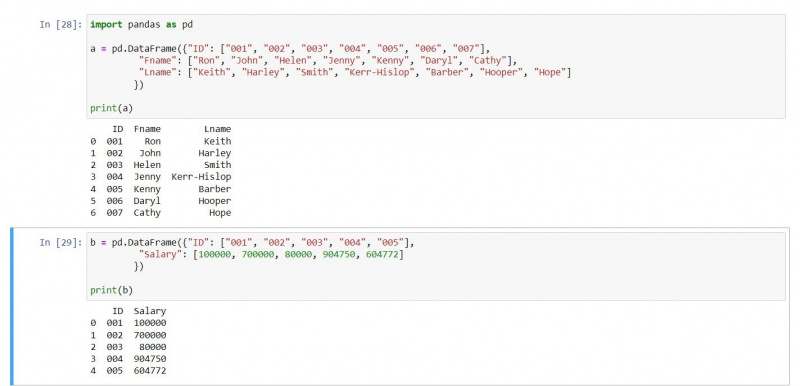
Notranje združevanje zagotavlja ujemajoče se vnose iz obeh DataFramesov. Ker združevanja uporabljajo številke indeksa za ujemanje vrstic, vrne notranje združevanje samo vrstice, ki se ujemajo. Za to ilustracijo uporabimo naslednja dva podatkovna okvira:
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)Rezultat je naslednji:
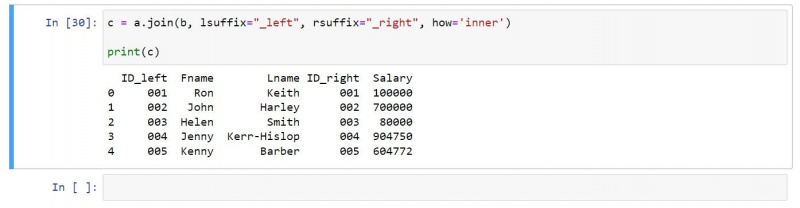
Notranje združevanje lahko uporabite na naslednji način:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)Končni izhod vsebuje samo vrstice, ki obstajajo v obeh vhodnih podatkovnih okvirih:
4. Zunanji spoj
Zunanje združevanje vrne vse vrednosti iz obeh DataFrames. Za vrstice brez ujemajočih se vrednosti v posameznih celicah ustvari ničelno vrednost.
Z uporabo istega podatkovnega okvira kot zgoraj je tukaj koda za zunanje združevanje:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)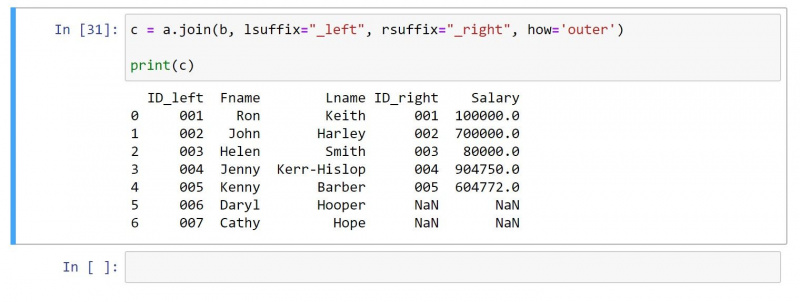
Uporaba spojin v Pythonu
Združevanja, tako kot njihovi nasprotni funkciji, združevanje in povezovanje, ponujajo veliko več kot preprosto funkcijo združevanja. Glede na vrsto možnosti in funkcij lahko izberete možnosti, ki ustrezajo vašim zahtevam.
Nastale nize podatkov lahko razvrstite razmeroma enostavno, z ali brez funkcije združevanja, s prilagodljivimi možnostmi, ki jih ponuja Python.